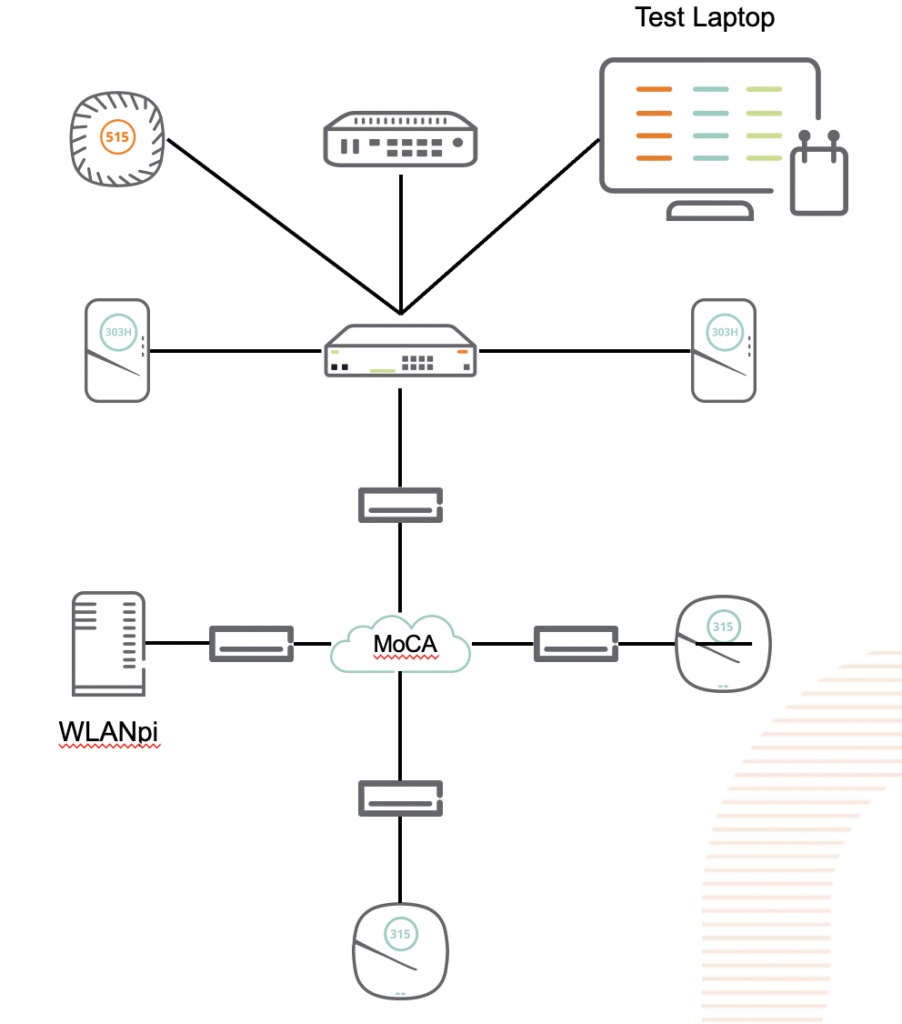
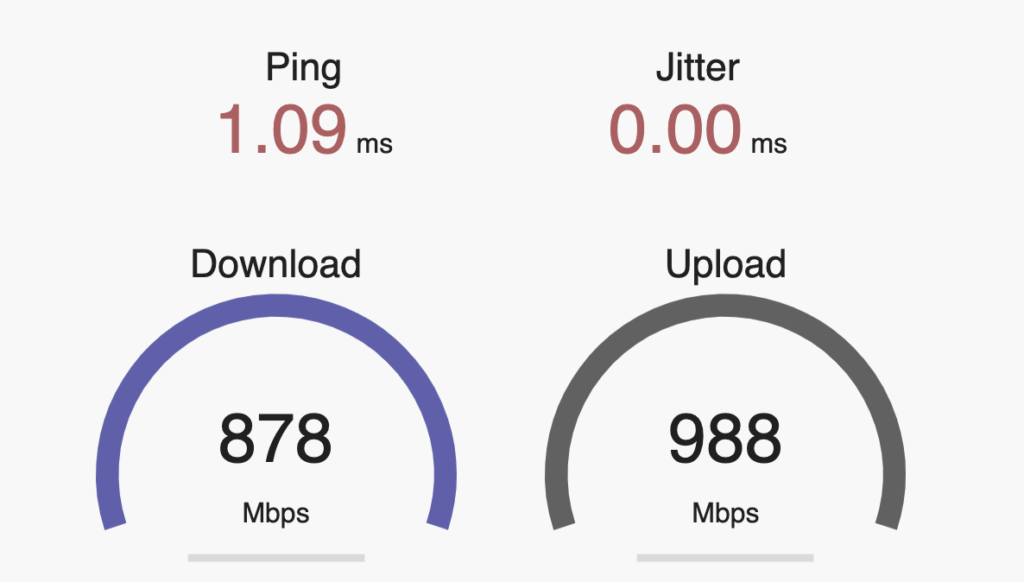
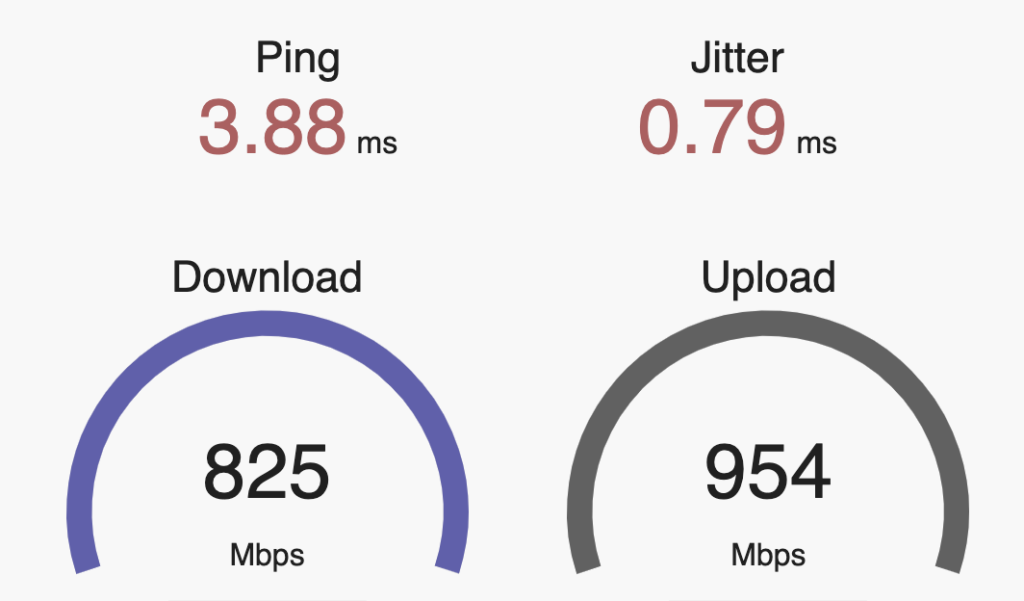
Having spent most of the last 5 years steeped in the HPE/Aruba networking ecosystem, I didn’t pay much attention to what Ubiquiti has been doing, as their primarily Prosumer and small business market segment didn’t significantly overlap with the large global customers I was working with at Aruba. HPE did venture into the SMB space with the InstantON product line, and have been reasonably successful at it, but the consulting work I was doing rarely went anywhere near that space. Now that I’m free of any competitive constraints. I’m taking another look at a product line that has clearly evolved.
About a year or so ago, I saw a marketing slide that surprised me, indicating that the #3 player in the Wi-Fi space (measured by total access points deployed) behind 800-pound gorilla Cisco and #2 Aruba, was, in fact, Ubiquiti.
Ubiquiti is a company that originally made a name for themselves by selling proprietary (AirMax) Wi-Fi-ish point-to-point and service provider gear, and eventually jumped into Wi-Fi. They quietly built themselves into a nearly US$2B/year operation by selling inexpensive (but broadly adequate) Wi-Fi hardware that appealed to small businesses, and they were largely ignored by the “Big Players” for years.
It had long been my own experience that the Ubiquiti ecosystem was decent but had some significant scalability limitations in terms of their management platform. This was especially clear after I got down and dirty with some absolutely massive deployments while working at Aruba. Over the years prior, I’ve deployed a number of Ubiquiti-based solutions and periodically watched them release a few products that were real stinkers (both hardware and software) or distractions from the core product line (anyone remember mFi? their solar product? the first 802.11ac access point to ship?). They gained a reputation (and it was largely deserved) by marketing the product as plug-and-play that required minimal engineering skill, along with a bunch of defaults that really weren’t doing anyone much good. They were the “cheap” brand, preferred by minimally competent “trunk-slammers” and customer bean counters and IT departments who didn’t really understand Wi-Fi, leading to a lot of really bad installations. They were also plagued by supply chain and quality challenges for a very long time.
But over the last several years, other consumer-focused companies like Netgear, TP-Link, Linksys (fresh off the utter debacle that was Cisco’s ownership of the brand), new players like Google (Nest) and Amazon (Eero), and eventually larger legacy players like Aruba (InstantON) started realizing that Ubiquiti did in fact have the prosumer market largely locked up. They decided they wanted a piece of that pie, right around the same time that the consumer market started realizing that it needed multi-AP solutions, especially in the US market where homes were growing ever larger, and all the while, ISPs were providing equipment was almost criminally cheap and awful.
This new competition ultimately proved to be a good thing for Ubiquiti, as complacency had been taking hold. The competition breathed new life into the company, who began to make some really smart hiring decisions on the product and development side.
Meanwhile, the founder of Ubiquiti, Robert Pera, decided to do as so many company founders with mountains of wealth do, and invested some of it into a professional sports team, the Memphis Grizzlies of the National Basketball Association. Along with the team came the management and operation of their home arena, the FedExForum. As it would never do for a competitor’s networking product to be in the arena, the team set about deploying Ubiquiti’s Wi-Fi product to serve the arena, at a scale that the product had never been deployed before. This ultimately proved that the product can in fact scale, if given the proper engineering attention by someone who actually knows what they’re doing (their lead network architect is a good friend and colleague), and product support and development that can integrate feedback and the unique challenges posed by Large Public Venues. This gave the hardware and software some much-needed improvements.
Most recently, Ubiquiti put in a long-awaited appearance at Mobility Field Day 11, and got to present their product portfolio and roadmap to deeply experienced professionals in the wireless network space. They came to announce that they have been listening to extensive feedback from Wi-Fi pros (including yours truly), and how they’re starting to make moves into offering truly enterprise-grade products and services. In doing so, they’ve announced that they’re coming to play, and I’m hopeful that they provide some much-needed competition to the likes of Cisco (especially Meraki), Aruba, Juniper, Extreme, and Ruckus, in the same way the consumer players did for them. The big players have gotten complacent too, and it’s high time the market got shaken up.
I was fortunate enough to be part of the beta test audience for their MFD presentation and received a rather generous shipment of lab equipment in exchange for my time and expertise. Over the next several posts, I’ll go over the unboxing and commissioning of the gear and provide my thoughts on it. Stay tuned!