
There’s a common saying among my network engineering peers: “It’s ALWAYS DNS!”. For those not familiar with the concept, this refers to the alarming regularity with which networking troubles end up being caused by something trivial, such as name resolution. And when it’s not DNS, it’s usually DHCP. Those two troublemakers alone are responsible for some ridiculously large percentage of network support issues. (At least until someone at a tier 1 provider inserts a typo into a route table advertised to half the internet via BGP, and takes everything down, but I digress.)
Last weekend, I rebuilt my home wireless network from an Aruba Instant cluster back to a controller based network, using ClearPass as an authentication and authorization backend for the home network. Gross overkill for a home network, but it gives me stick time on stuff that I need to know for work, at a much grander scale.

But first, a little background into the Aruba Way of doing things: In an Instant cluster, the wireless networks are bridged to a VLAN that is trunked to the access point. You can also do this with campus networking, but managing all those VLANs on every port that feeds an access point is usually a recipe for forgetting something vital. So the campus model lets you build a single access VLAN on your AP ports, and the AP establishes a GRE tunnel back to the controller cluster (which also allows for some great redundancy and high availability options), and the various VLANs terminate on the user anchor controllers (because each user has their own tunnel back to the controller, which allows you to segment their traffic out and handle it at layers 4-7 based on a variety of rules, and the only thing going over the wire is an encrypted tunnel, which is a significantly better security posture should someone unethically decide to monitor traffic on a switch port when they shouldn’t.
This is also where ClearPass comes into play – How user sessions and traffic are handled is defined in roles. Each role consists of various rules. How roles are applied are defined by policies. You can map roles to users and/or machines with the magic of ClearPass, and then when someone connects to the wireless network, ClearPass can return a role (and it can map a different role based on whether you authenticated with a username/password, a certificate, or any one of a number of other data inputs). Basically, when ClearPass returns the OK to the controller, it also includes a bunch of attributes for that user, including roles. It’s extremely powerful magic, and when wielded wrong, it can cause no end of heartache trying to figure out just what exactly went haywire. And I’m still very much a ClearPass n00b.
Which brings me back to my newly built and ClearPass-enabled network. And so like every good story…
No $#!+, there I was…
When I connected, it would take a good 10 minutes before I could access the internet. And so, I’m wondering what I screwed up in my ClearPass setup that would have done this… But the roles were being assigned correctly, and the rules associated with those roles were pretty straightforward: “allow all”. So why in the heck were devices on the home network taking forever and a week to get an address? This was not happening on my IoT and guest networks.
First, I realized that my devices were associating just fine, so ClearPass and the role derivation were working correctly, which immediately acquitted the Wi-Fi (but as far as the others in my house were concerned, the Wi-Fi was still screwed up). But that meant I had a good Layer 2 connection. I tried to make sure that the VLAN was properly connected from the pfSense router to the core switch, and the controllers (running in VMWare) were properly trunking to the distributed vSwitch and also out to the core switch. Everything on that front looked good. I tried manually assigning IPs to the wireless clients on the home LAN, and they worked great. So L3 worked, which implied L2 did as well. And when clients on the home network did eventually get an IP address, they worked fine as well. So nothing was being bottlenecked anywhere either (I should hope not, as the VMWare hosts and the router are all connected to the core switch with dual 10-gigabit fiber links!).
After a few days of racking my brain over this, and hearing the people who live in my house continue to complain about network weirdness (thankfully, my family is not doing virtual school/work… except for me), I finally resigned myself to doing what I should have done in the first place: Breaking out Wireshark and figure out just what was actually happening on the network. DHCP is pretty simple, so finding out what broke should be straightforward, right?
Quick refresher on DHCP: The process of obtaining a DHCP address goes like this:
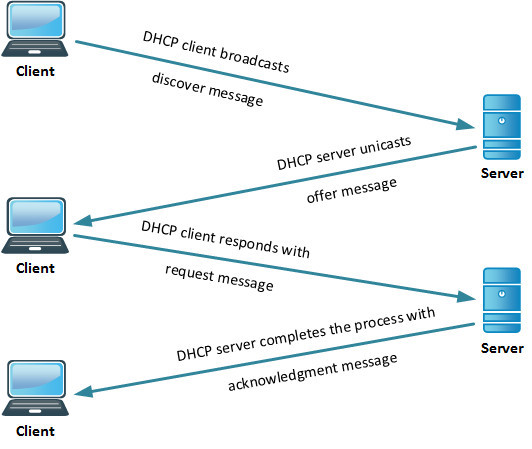
Since I knew I had good L2 connectivity, I fired up Wireshark on my laptop, capturing what was going on at L2, and would move to other points in the network if I needed to. The first thing I saw is that a residential network, even with isolated guest and IoT traffic, while nobody else in the house is using it, is a fairly chatty place. I saw a bunch of multicast traffic (I have a lot of Apple devices), even IP broadcast traffic. And there, among all that, was the DHCP process. Discover. Discover. Discover. Offer. Request. Request. Request. Discover. Discover. Offer. Request. Request. Request. Discover. Discover. Discover. Offer. Request. Request. Request. The more astute among you may have noticed something missing from this sequence. Something rather… important.

Turns out, my DHCP server was making an offer, and then ghosting my devices as soon as they responded to that offer. And periodically, a DHCP ACK would sneak through. And by now, it had started happening on my IoT network as well, as half my Nest Protect alarms were now showing offline. But that told me one very important thing: that my DHCP server was in fact online, reachable, and responding. Up until that very last point.
So I then did what any sane engineer would do:

I had already restarted the dhcpd on my pfSense box, so I didn’t have much faith in the curative effects of a digital boot to the head, but what the heck, can’t hurt, right?
And that’s when I saw it. I went down to my lab, and there, on the front of the DL360 that is running my router, is an angry orange light which should normally be a happy little green. Uh-oh.

So, I pop out the handy little SID tray, to see what it’s angry about… And this is not something a server admin wants to see:

Yep, that’s flagging all three memory modules in Processor 1’s Bank A. This just became more than a simple reboot. Sure enough, when it went through POST, it flagged all three modules. Power off, slide out the server (rails FTW), and perform that tried and true troubleshooting method I learned and perfected in the Air Force a quarter century ago: Swaptronics. Move a suspected bad component and see if the problem follows. So, I switched all the DIMMs from bank A with those in Bank B. If the fault stayed with Bank A, then I had a bum system board. If the fault followed the DIMMs to Bank B, then the fault was in the DIMMs. I really wanted the fault to follow the DIMMs.
Plug it all back in, and fire it up, and the fault was…
NOW IN BANK B!!!! Hallelujah, I don’t have a bad server on my hands!

So now I shut it down, tossed the bad DIMMs in the recycling bin (yes, our recycling pickup actually takes e-waste, which is really nice when you’re a nerd with way too many electronic bits), and repopulated/balanced the banks (I also had to remove a fourth DIMM to keep things even, but it’s a known good part, so it did not go to recycling).

I fire the machine back up, and yay, it’s no longer grumpy about the bad memory, although it is briefly perplexed by the fact that it now only has 24GB instead of 32GB, and has somehow realized that it just had a partial lobotomy. After a few minutes of much more intensive self-testing than usual, it boots up pfSense, and gives me the happy beeps that pfSense does when it’s fully booted (for those of us who run our pfSense boxes headless!)
The moment of truth: I connect my laptop to the Wi-Fi (with the wireshark still circling)… and sure enough, the DHCP ACK comes through on the first try… So as near as I can tell, whatever part of the system RAM contained the bit of code required to send the DHCP ACK had suffered some kind of stroke, but not one severe enough to take the whole box or even the operating system down.
See? It’s always DHCP.
EDIT: Turns out there was also more to this – Wired clients (and access points) started getting DHCP right away after fixing this, but wireless was still giving me fits. As it turned out, There was something about the Aruba mobility controllers terminating user sessions that played havoc with the hashing algorithms that VMWare uses to handle NIC teaming on switch uplinks, and the ACKs were coming back through a different path and getting lost along the way.
For the moment, I disabled one of the 10G links to the switch until I can figure out what magic incantations I need to make on the vSwitch to get the hashing algorithms to properly use the multiple connections with the VMCs – or I may just use the second 10G interfaces for vMotion or something.
and that, kids, is how I used Wireshark to diagnose a system memory problem.
Hi Ian, I liked your article , vewry informative and parctical which is not always the case …
Cheers
Alain
Thanks for the write up Ian. Nice troubleshooting. Sorry about your modules.