Yep. Another post about code. No, I’m not a software developer, I’m just a lazy network engineer who has an allergic reaction to doing GUI-based management of large environments. And thus I code because that’s a growing part of being a network engineer in the 2022.
A recent client project involving deploying a large fleet of Remote Access Points for teleworkers has required me to look at the Aruba Central API as a way of simplifying and streamlining the deployment of these APs to ensure consistency and completeness of the deployment. If you’re going to do anything more than about 5 times, it’s worth trying to automate it. If you’re going to do it 5000 times, you should automate it. I’m starting to get the hang of the AOS8 API and its many quirks, but Central is much more API-first than AOS8 which uses the API primarily as a frontend to the CLI.
If you have a remote workforce that depends on secure connections back to the corporate network, you should definitely check out the Aruba RAP solution. It beats the pants off software VPN clients (and at this point, how many teleworkers are even still wearing pants?). This solution has been available since almost the very beginning of Aruba nearly 2 decades ago and is mature and robust.
Like all of Aruba’s platforms, Central has a REST API that allows automation. The web frontend is essentially leveraging this API to work its magic. Aaron Scott, an Aruba CSE in Australia, has even built his own frontend to Aruba Central, because you can do that sort of thing when you have an API.
It’s got Swagger!
The Central API, like most, is documented with Swagger which allows you to browse and try various API calls to see how they behave.
I won’t rehash how to get access to it here, because Aruba documents the process very well in the Developer Hub page:
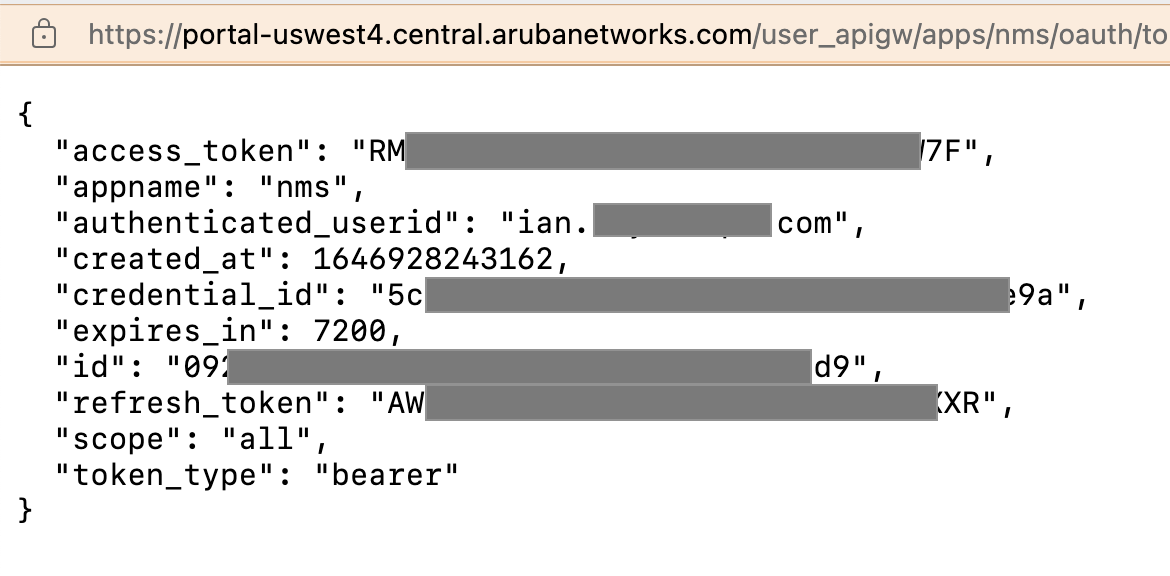
Note: once you’ve generated your token, make sure you download it by clicking “Download Token”. It will open a new window containing the JSON text with the actual token in it. Save this to a text file which you can use with your scripts later. Note the expiration time on this: 7200 seconds. This token isonly good for two hours. You will need to use the refresh token in there to keep it alive past the 2 hour window. The refresh token is good for 15 days. How? It’s in the docs listed above (yeah, I just dropped an RTFM on you!)
Programming with the API
(and a gratuitous plug for the Aruba Developer Hub)
If you want to access the API programmatically, you’ll want to use Python, although anything capable of making HTTP calls and processing JSON responses will work. Fortunately, Aruba has provided a Python library (again, on the Aruba Developer Hub – this site has a wealth of great stuff).
The documentation on how to install the Python libraries can be found on the Developer Hub. At some point, you’ll likely be referred to the documentation for the library on Read The Docs. This documentation is broadly good, but in some places omits a few key points. Most notably, any time you need to send data to the API in a POST call, it’s not immediately apparent that body data needs to go into the apiData parameter.
Plenty of examples on the Dev Hub, and what you do will depend on your workflow and what you’re trying to accomplish. It may be helpful to draw yourself a mind map of what steps are needed to perform a task, and then map out what API calls and Python classes are required to make them, as well as what input data it depends on. Practice good code hygiene and don’t ever put your tokens in your code lest you accidentally share it to the world when you share your code (this is partly why the tokens on Aruba Central are only good for 2 hours!). Instead refer to the token file I suggested you download earlier (which you can do simply by opening the file and doing a json.load to import the contents into a dict.)
It’s also worth noting that the Aruba Central API does not provide you with any access to the Aruba Activate provisioning system (this is a bit of an annoyance to me, but out of my control). This has recently been given a major overhaul and has been migrated to the HPE GreenLake Platform and is now under the GreenLake device management function. There is an API for many GreenLake functions (see also: the HPE Developer Hub), but from what I understand, the platform is presently still migrating the API. I’ll update the post as soon as it’s available. (and did you know that if you have HPE servers, the ILO management subsystem also has a REST API? API ALL THE THINGS!)
If you’ve been using Ekahau for a while, you probably already know how painful it can be to generate a list of APs from within a custom report template – and even then, it’s not the most useful thing in the world just for being in Word format.
In my previous posts about the ArubaOS API, I’ve given a general framework for pulling data from the AOS Mobility Conductor or a Mobility Controller. Today I’m going to show how to retrieve the AP database and dump it into a CSV file which you can then open in Excel or anything else and work all kinds of magic (yes, I know, Excel is not a database engine, but it still works rather well with tabular data)
The long-form AP database command (show ap database long) provides lots of useful information about the APs in the system:
AP Name
AP Group
AP Model
AP IP Address
Status (and uptime if it’s up)
Flags
Switch IP (primary AP Anchor Controller)
Standby IP (standby AAC)
AP Wired MAC Address
AP Serial #
Port
FQLN
Outer IP (Public IP when it is a RAP)
User
This script will take the human-readable uptime string (“100d:12h:34m:28s”) and convert that to seconds so uptime can be sorted in your favorite spreadsheet. It will also create a grid of all the AP flags so that you can sort/filter on those after converting the CSV to a data table.
The code is extensively commented so you should be able to follow along. Also available on github.
#!/usr/bin/python3
# ArubaOS 8 AP Database to CSV output via API call
# (c) 2021 Ian Beyer, Aruba Networks <canerdian@hpe.com>
# This code is provided as-is with no warranties. Use at your own risk.
import requests
import json
import csv
import sys
import warnings
import sys
import xmltodict
import datetime
aosDevice = "1.2.3.4"
username = "admin"
password = "password"
httpsVerify = False
outfile="outputfilename.csv"
#Set things up
if httpsVerify == False :
warnings.filterwarnings('ignore', message='Unverified HTTPS request')
baseurl = "https://"+aosDevice+":4343/v1/"
headers = {}
payload = ""
cookies = ""
session=requests.Session()
## Log in and get session token
loginparams = {'username': username, 'password' : password}
response = session.get(baseurl+"api/login", params = loginparams, headers=headers, data=payload, verify = httpsVerify)
jsonData = response.json()['_global_result']
if response.status_code == 200 :
#print(jsonData['status_str'])
sessionToken = jsonData['UIDARUBA']
else :
sys.exit("Login Failed")
reqParams = {'UIDARUBA':sessionToken}
def showCmd(command, datatype):
showParams = {
'command' : 'show '+command,
'UIDARUBA':sessionToken
}
response = session.get(baseurl+"configuration/showcommand", params = showParams, headers=headers, data=payload, verify = httpsVerify)
if datatype == 'JSON' :
#Returns JSON
returnData=response.json()
elif datatype == 'XML' :
# Returns XML as a dict
returnData = xmltodict.parse(response.content)['my_xml_tag3xxx']
elif datatype == 'Text' :
# Returns an array
returnData =response.json()['_data']
return returnData
apdb=showCmd('ap database long', 'JSON')
# This is the list of status flags in 'show ap database long'
apflags=['1','1+','1-','2','B','C','D','E','F','G','I','J','L','M','N','P','R','R-','S','U','X','Y','c','e','f','i','o','s','u','z','p','4']
# Create file handle and open for write.
with open(outfile, 'w') as csvfile:
write=csv.writer(csvfile)
# Get list of data fields from the returned list
fields=apdb['_meta']
# Add new fields for parsed Data
fields.insert(5,"Uptime")
fields.insert(6,"Uptime_Seconds")
# Add fields for expanding flags
for flag in apflags:
fields.append("Flag_"+flag)
write.writerow(fields)
# Iterate through the list of APs
for ap in apdb["AP Database"]:
# Parse Status field into status, uptime, and uptime in seconds
utseconds=0
ap['Uptime']=""
ap['Uptime_Seconds']=""
# Split the status field on a space - if anything other than "Up", it will only contain one element, first element is status description.
status=ap['Status'].split(' ')
ap['Status']=status[0]
# Additional processing of the status field if the AP is up as it will report uptime in human-readable form in the second half of the Status field we just split
if len(status)>1:
ap['Uptime']=status[1]
#Split the Uptime field into each time field and strip off the training character, multiply by the requisite number of seconds an tally it up.
timefields=status[1].split(':')
# If by some stroke of luck you have an AP that's been up for over a year, you might have to add a row here - I haven't seen how it presents it in that case
if len(timefields)>3 :
days=int(timefields.pop(0)[0:-1])
utseconds+=days*86400
if len(timefields)>2 :
hours=int(timefields.pop(0)[0:-1])
utseconds+=hours*3600
if len(timefields)>1 :
minutes=int(timefields.pop(0)[0:-1])
utseconds+=minutes*60
if len(timefields)>0 :
seconds=int(timefields.pop(0)[0:-1])
utseconds+=seconds
ap['Uptime_Seconds']=utseconds
# FUN WITH FLAGS
# Bust apart the flags into their own fields
for flag in apflags:
# Set field to None so that it exists in the dict
ap["Flag_"+flag]=None
# Check to see if the flags field contains data
if ap['Flags'] != None :
# Iterate through the list of possible flags and mark that field with an X if present
if flag in ap['Flags'] :
ap["Flag_"+flag]="X"
# Start assembling the row to write out to the CSV, and maintain order and tranquility.
datarow=[]
# Iterate through the list of fields used to create the header row and append each one
for f in fields:
datarow.append(ap[f])
# Put it in the CSV
write.writerow(datarow)
#Move on to the next AP
# Close the file handle
csvfile.close()
## Log out and remove session
response = session.get(baseurl+"api/logout", verify=False)
jsonData = response.json()['_global_result']
if response.status_code == 200 :
#remove
token = jsonData['UIDARUBA']
del sessionToken
else :
del sessionToken
sys.exit("Logout failed:")
The human-readable output of the show ap database gives you a list of what the flags are, but the API call does not, so in case you want a handy reference, here it is in JSON format so that you can easily adapt it. (Github)
sheldon={
'1':'802.1x authenticated AP use EAP-PEAP',
'1+':'802.1x use EST',
'1-':'802.1x use factory cert',
'2':'Using IKE version 2',
'B':'Built-in AP',
'C':'Cellular RAP',
'D':'Dirty or no config',
'E':'Regulatory Domain Mismatch',
'F':'AP failed 802.1x authentication',
'G':'No such group',
'I':'Inactive',
'J':'USB cert at AP',
'L':'Unlicensed',
'M':'Mesh node',
'N':'Duplicate name',
'P':'PPPoe AP',
'R':'Remote AP',
'R-':'Remote AP requires Auth',
'S':'Standby-mode AP',
'U':'Unprovisioned',
'X':'Maintenance Mode',
'Y':'Mesh Recovery',
'c':'CERT-based RAP',
'e':'Custom EST cert',
'f':'No Spectrum FFT support',
'i':'Indoor',
'o':'Outdoor',
's':'LACP striping',
'u':'Custom-Cert RAP',
'z':'Datazone AP',
'p':'In deep-sleep status',
'4':'WiFi Uplink'
}
Another quick bit today – this is the basic framework for using the REST API in ArubaOS. Lots of info at the Aruba Developer Hub. This is primarily for executing show commands and getting the data back in a structured JSON format.
However, be aware that not all show commands return structured JSON – some will return something vaguely XMLish, and some will return the regular text output inside a JSON wrapper (originally the showcommand API endpoint was just a wrapper for the actual commands and would just return the CLI output, as it still does for several commands)
You can always go to https://<controller IP>:4343/api (after logging in) and get a Swagger doc for all the available API calls – although owing to system limitations, the description of those endpoints isn’t generally there, but it can be found in the full AOS8 API reference.
This blog entry does not deal with sending data to the ArubaOS device.
Yesterday, I posted about leveraging the Meridian API to get a list of placemarks into a CSV file. Today, We’ll take that one step further, and go the other way – because bulk creating/updating placemarks is no fun by hand.
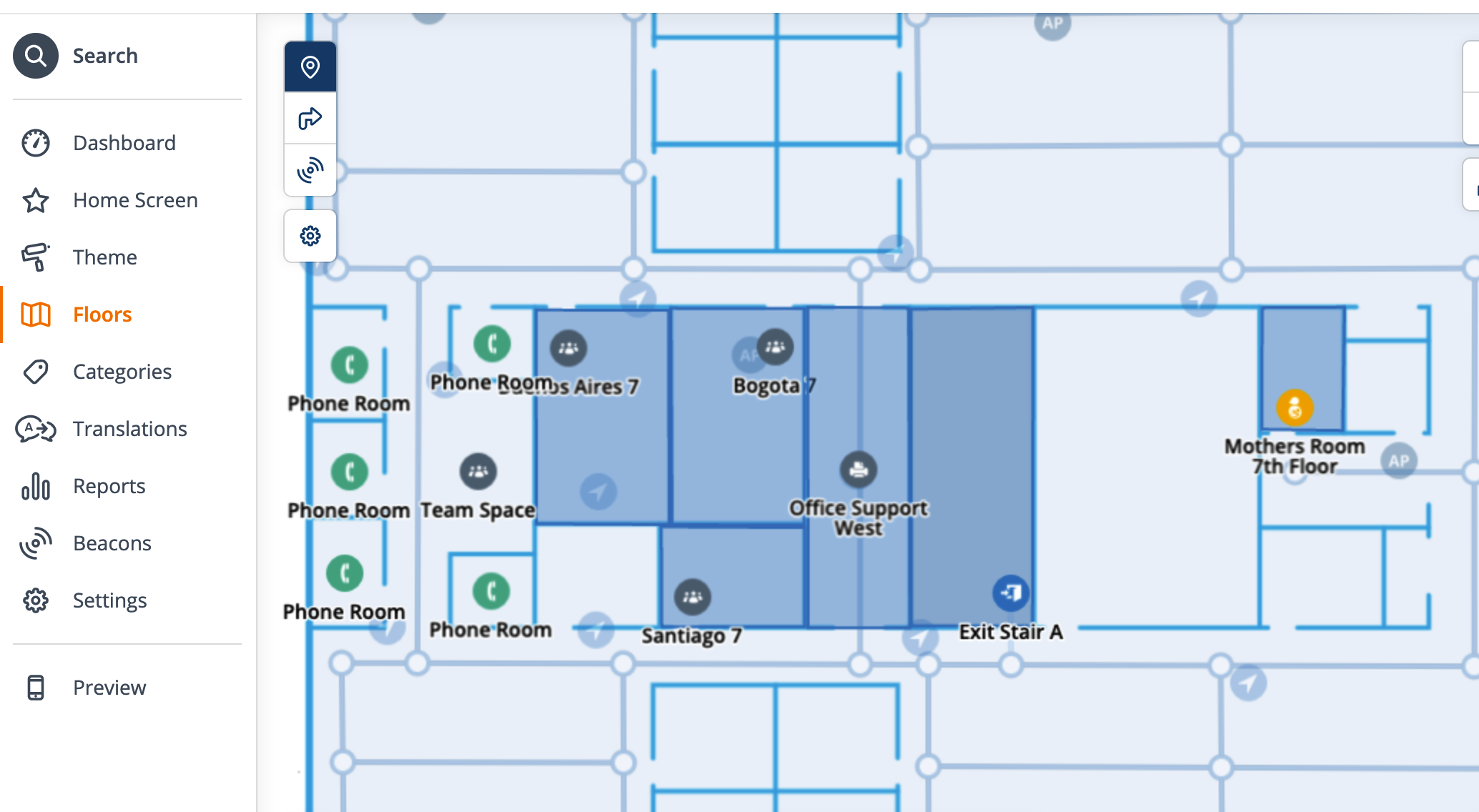
For instance, in this project, I created a bunch of placemarks called “Phone Room” (didn’t know what else to call them at the time). There were several of these on multiple floors. To rename them in the Meridian Editor, I would have to click on each one, rename it, and save.
So, once I got guidance on what they were to be called, I fired up Excel and opened up the CSV that I created yesterday, and made the changes in bulk, and then ran them back into Meridian the other way – I changed the name, the type, and the icon:
Sounds easy, right?
Not so much. I ran into some trouble when I opened it in excel, and all my map IDs looked like this:
This is because Excel is stupid, but trying to be smart. It sees those as Really Big Numbers, and converts them to scientific notation, because the largest it can store is a 15-digit integer. And of course, these map IDs are… 16 digits. But I can’t just convert them back as integer number formatting because it then takes the first 15 digits and adds a zero. This, of course, breaks the whole thing. Excel will also do some similar shenanigans when parsing interface names from AOS or Cisco that look like “2/1/4”, which excel assumes is a date, because excel assumes everything that looks vaguely numeric must be a number, because it is a spreadsheet after all, and spreadsheets are made for numbers, even if people abuse them all the time as a poor substitute for a database.
So, this means you either have to make the changes directly in the CSV with a text editor, or find another sheets application that doesn’t mangle the map IDs. Fortunately, for us Mac users, Apple’s spreadsheet application (“Numbers”) handles this just fine. So make the changes, export to CSV, and run it all back into the API. (you can also name it as a .txt and manually import into Excel and specify that as a text column, but that’s tedious, which is what we’re trying to avoid)
I’ve built a bit of smarts into this script, since I don’t want to break things on Meridian’s end (although Meridian does a great job of sanity checking and sanitizing the input data from the API). The first thing it does is grab a list of available maps for the location. Then it goes through all the lines in the spreadsheet, converts them to the JSON payload that Meridian wants, and checks to see if there’s existing data in the id field. If there is, it assumes that this is an update (it does not, however, check to see if the data already matches the existing placemark since Meridian does that already when you update). If there is no ID, it assumes that this is a new object to be created, and verifies that it has the minimum required information (name, map, and x/y position), and in both cases, checks to make sure the map data in the object is a map ID that exists at this location (this is how I found out that excel was mangling them)
Running the script spits out this for each row in the CSV that it considers an update:
Update object id XXXXXXXXXXXXXXX_5666694473318400
object update passed initial sanity checks and will be placed on 11th Floor.
Updating existing object with payload:
{
"id": "XXXXXXXXXXXXXXX_5666694473318400",
"name": "Huddle Space",
"map": "XXXXXXXXXXXXXXX",
"type": "conference_room",
"type_name": "Conference Room",
"color": "f2af1d",
"x": "177.20516072322900",
"y": "597.6184874989240",
"latitude": 41.94822,
"longitude": -87.65552,
"area": "",
"description": "",
"phone": "",
"email": "",
"url": ""
}
Object ID XXXXXXXXXXXXXXX_5666694473318400 named Huddle Space updated on map XXXXXXXXXXXXXXXX
If it doesn’t find an id and determines that an object needs to be created, it goes down like this:
Create new object:
object create passed initial sanity checks and will be placed on 11th Floor.
Creating new object with payload:
{
"name": "Test Placemark",
"map": "XXXXXXXXXXXXXXXX",
"type": "generic",
"type_name": "Placemark",
"color": "f2af1d",
"x": "400",
"y": "600",
"latitude": "",
"longitude": "",
"area": "",
"description": "",
"phone": "",
"email": "",
"url": "https://arubanetworks.,com"
}
Object not created. Errors are
{
"url": [
"Enter a valid URL."
]
}
As you can see here, I made a typo in the URL field, and the data returned from the API call lists the fields that contain an error. If the call is successful, it returns an ID, which the script checks for to verify success. The response from a successful API call looks like this :
Of course, the script doesn’t have to spit out all that output, but it’s handy to follow what’s going on. Comment out the print lines if you want it to shut up.
So, without further ado, here’s the script. This has not been debugged extensively, so use at your own risk. If you break your environment, you probably should have tested it in the lab first.
#!/usr/bin/python3
# Aruba Meridian Placemark Import from CSV
# (c) 2021 Ian Beyer
# This code is not endorsed or supported by HPE
import json
import requests
import csv
import sys
auth_token = '<please insert a token to continue>'
location_id = 'XXXXXXXXXXXXXXXX'
baseurl = 'https://edit.meridianapps.com/api/locations/'+location_id
header_base = {'Authorization': 'Token '+auth_token}
def api_call(method,endpoint,headers,payload):
response = requests.request(method, baseurl+endpoint, headers=headers, data=payload)
resp_json = json.loads(response.text)
return(resp_json)
#File name argument #1
try:
fileName = str(sys.argv[1])
except:
print("Exception: Enter file to use")
exit()
# Get available maps for this location for sanity check
maps={}
# print("Available Maps: ")
for floor in api_call('GET','/maps',header_base,{})['results']:
maps[floor['id']] = floor['name']
# print (floor['name']+ ": "+ floor['id'])
import_data_file = open(fileName, 'rt')
csv_reader = csv.reader(import_data_file)
count = 0
objects = []
csv_fields = []
for line in csv_reader:
placemark = {}
# Check to see if this is the header row and capture field names
if count < 1 :
csv_fields = line
else:
# If this is a data row, capture the fields and put them into a dict object
fcount = 0
for fields in line:
objkey = csv_fields[fcount]
placemark[objkey] = line[fcount]
fcount += 1
# Add the placemark object into the object list
objects.append(placemark)
count +=1
#print(json.dumps(objects, indent=2))
import_data_file.close()
#Check imported objects for create or update. If it has an ID, then update.
for pm in objects:
task = 'ignore'
if pm['id'] == "" :
task = 'create'
print("Create new object: ")
# Delete id from payload
del pm['id']
else:
task = 'update'
print("Update object id "+ pm['id'])
# Remove floor from payload as it is not valid
del pm['floor']
# Check to see if the basics are there before making the API calls
reject = []
if pm['x'] == "":
reject.append("Missing X coordinate")
if pm['y'] == "":
reject.append("Missing Y coordinate")
if pm['map'] == "":
reject.append("Missing map id")
if pm['name'] == "":
reject.append("Missing object name")
if len(reject)>0:
#print("object "+ task + " rejected due to missing required data:")
for reason in reject:
print(reason)
task = 'ignore'
else:
if maps.get(pm['map']) == None:
print ("Map ID "+pm['map']+" Not found in available maps. Object will not be created. ")
task = 'ignore'
else:
print("object "+ task + " passed initial sanity checks and will be placed on "+ maps[pm['map']] +".")
#print ("Object Payload:")
#print (json.dumps(pm, indent=2))
method = 'GET'
if task == 'create':
#print ("Creating new object with payload:")
#print (json.dumps(pm, indent=2))
method = 'POST'
ep = '/placemarks'
result = api_call(method,ep,header_base,pm)
if result.get('id') != None:
print ("Object ID "+result['id']+" named "+result['name']+ " created on map "+ result['map'])
else:
print ("Object not created. Errors are")
print (json.dumps(result, indent=2))
if task == 'update':
#print ("Updating existing object with payload:")
#print (json.dumps(pm, indent=2))
method = 'PATCH'
ep = '/placemarks/'+pm['id']
result = api_call(method,ep,header_base,pm)
if result.get('id') != None:
print ("Object ID "+result['id']+" named "+result['name']+ " updated on map "+ result['map'])
else:
print ("Object not updated. Errors are")
print (json.dumps(result, indent=2))
baseurl = 'https://edit.meridianapps.com/api/locations/'+location_id
header_base = {'Authorization': 'Token '+auth_token}
def api_call(method,endpoint,headers,payload):
response = requests.request(method, baseurl+endpoint, headers=headers, data=payload)
resp_json = json.loads(response.text)
return(resp_json)
# Get available maps for this location for sanity check
maps={}
# print("Available Maps: ")
for floor in api_call('GET','/maps',header_base,{})['results']:
maps[floor['id']] = floor['name']
# print (floor['name']+ ": "+ floor['id'])
# I've hard coded the file name here because I'm lazy.
import_data_file = open('placemarks_update.csv', 'rt')
csv_reader = csv.reader(import_data_file)
count = 0
objects = []
csv_fields = []
for line in csv_reader:
placemark = {}
# Check to see if this is the header row and capture field names
if count < 1 :
csv_fields = line
else:
# If this is a data row, capture the fields and put them into a dict object
fcount = 0
for fields in line:
objkey = csv_fields[fcount]
placemark[objkey] = line[fcount]
fcount += 1
# Add the placemark object into the object list
objects.append(placemark)
count +=1
#print(json.dumps(objects, indent=2))
import_data_file.close()
#Check imported objects for create or update. If it has an ID, then update.
for pm in objects:
task = 'ignore'
if pm['id'] == "" :
task = 'create'
print("Create new object: ")
# Delete id from payload
del pm['id']
else:
task = 'update'
print("Update object id "+ pm['id'])
# Remove floor from payload as it is not valid
del pm['floor']
# Check to see if the basics are there before making the API calls
reject = []
if pm['x'] == "":
reject.append("Missing X coordinate")
if pm['y'] == "":
reject.append("Missing Y coordinate")
if pm['map'] == "":
reject.append("Missing map id")
if pm['name'] == "":
reject.append("Missing object name")
if len(reject)>0:
#print("object "+ task + " rejected due to missing required data:")
for reason in reject:
print(reason)
task = 'ignore'
else:
if maps.get(pm['map']) == None:
print ("Map ID "+pm['map']+" Not found in available maps. Object will not be created. ")
task = 'ignore'
else:
print("object "+ task + " passed initial sanity checks and will be placed on "+ maps[pm['map']] +".")
#print ("Object Payload:")
#print (json.dumps(pm, indent=2))
method = 'GET'
if task == 'create':
#print ("Creating new object with payload:")
#print (json.dumps(pm, indent=2))
method = 'POST'
ep = '/placemarks'
result = api_call(method,ep,header_base,pm)
if result.get('id') != None:
print ("Object ID "+result['id']+" named "+result['name']+ " created on map "+ result['map'])
else:
print ("Object not created. Errors are")
print (json.dumps(result, indent=2))
if task == 'update':
#print ("Updating existing object with payload:")
#print (json.dumps(pm, indent=2))
method = 'PATCH'
ep = '/placemarks/'+pm['id']
result = api_call(method,ep,header_base,pm)
if result.get('id') != None:
print ("Object ID "+result['id']+" named "+result['name']+ " updated on map "+ result['map'])
else:
print ("Object not updated. Errors are")
print (json.dumps(result, indent=2))
It’s also worth noting here that the CSV structure and field order isn’t especially important since it reads in the header row to get the keys for the dict – as long as you have the minimum data (name/map/x/y) you can create a table of new objects from scratch. Any valid field can be used (although categories requires some additional structure)
While the web based editor is great, it is mildly annoying that one of the things it can’t do is copy and paste placemarks between floors, which would be really handy when you’re deploying an office building that has almost the same layout on every floor. For this, you have to dig into the Meridian API.
By using the API, you can spit out a list of placemarks in JSON (easiest way to do this is in Postman, with a GET to {{BaseURL}}/locations/{{LocationID}}/placemarks), grab the JSON objects for the placemarks you wish to copy from the output, update the fields in the JSON for which map ID they need to go on, and any other data, and then make a POST back to the same endpoint with a payload containing the JSON list of objects you want to create. Presto, now you’ve been able to clone all the placemarks from one floor to another.
Note that point coordinates are relative to the map image – So cloning from one map to another can bite you in the rear if they’re not properly aligned. (If you want to get really clever, You could manually create a placemark on every floor whose sole purpose is to align each floor in code – much like an alignment point in Ekahau, when you generate a placemark list, you can calculate any offsets between them and apply those to coordinates before sending them back to the API. But this trick could (and probably will) be a whole post of its own.
However, when creating a new placemark, you don’t need all these fields… The only objects that are absolutely required are map, type, x, and y (I haven’t tried sending an id along with a POST, so I don’t know if it will ignore it or reject it.) I’ve used Postman variables here for map and name, because then I could just change those in the environment variables and resubmit to put on multiple floors. The best part about the POST method is that the payload doesn’t just have to be a single JSON object, it can be a list of them, by simply putting multiple objects inside a list using square brackets.
And if you want to update an existing placemark, simply make a PATCH call to the API with the existing placemark’s ID, and whatever fields you wish to update. Like with the POST call, you can send a payload that is a list of objects This is a great way to batch update URLS or names.
It may also come in handy to generate a list of all the placemarks at a given location. So I threw together a handy little python script that will spit it out into a CSV (and will also look up the map ID and get the floor number for easy reference).
#!/usr/bin/python3
# Aruba Meridian Placemark Export to CSV
# (c) 2021 Ian Beyer
# This code is not endorsed or supported by HPE
import json
import requests
import csv
import sys
auth_token = 'Please Insert Another Token to continue playing'
location_id = 'XXXXXXXXXXXXXXXX'
baseurl = 'https://edit.meridianapps.com/api/locations/'+location_id
header_base = {'Authorization': 'Token '+auth_token}
def api_get(endpoint,headers,payload):
response = requests.request("GET", baseurl+endpoint, headers=headers, data=payload)
resp_json = json.loads(response.text)
return(resp_json)
#File name argument #1
try:
fileName = str(sys.argv[1])
except:
print("Exception: Enter file to use")
exit()
maps={}
for floor in api_get('/maps',header_base,{})['results']:
maps[floor['id']] = floor['name']
beacons=[]
# Iterate by floor for easy grouping -
for flr in maps.keys():
bcnlist=api_get('/beacons?map='+flr,header_base,{})
# NOTE: If bcnlist['next'] is not null, then there are additional pages - this doesn't process those yet.
for bcn in bcnlist['results']:
# Add floor name column for easier reading.
bcn['floor']=maps[bcn['map']]
beacons.append(bcn)
data_file = open(fileName, 'w')
csv_writer = csv.writer(data_file)
count = 0
csv_fields = beacons[0].keys()
print(csv_fields)
csv_writer.writerow(csv_fields)
#print(placemarks)
for bcn in beacons:
data=[]
for col in csv_fields:
data.append(bcn[col])
# Writing data of CSV file
csv_writer.writerow(data)
count += 1
data_file.close()
print ("Exported "+str(count)+" beacons. ")
Once you have this list in a handy spreadsheet form, then you can make quick and easy edits, and then run the process the other way.
Just this past week, Ekahau released the latest iteration of their excellent wireless network planning software, and with this version, they’ve added a few features that many of us have been wanting for quite some time. Of course, we always want more, and there’s only so much the elves at Ekahau can do! So this leaves us with building our own tools to extract the data we need out of the project file. (Hey, Ekahau, you know what would be really awesome? an SDK for doing this!)
Fortunately, Ekahau has been really good about building a standards-based project file format (and not encrypting it or doing things that make it a pain to use your own data). Since the Ekahau software is built in Java (cross platform on Windows/Mac!), it’s logical for the data file to be in something like XML or JSON, and they have chosen the latter, and have effectively built a relational database in JSON, and bundled the whole thing up into a convenient zip file. It’s almost like they understand that their core market is made up almost entirely of customers who like to tinker with things.
Disclaimers:
Naturally, manipulating this file is something to be done entirely at your own risk, and if you break it, don’t go crying to Ekahau, because they don’t support mucking with their data file outside of their application (nor should they be expected to!) Make sure you have backups, etc, etc.
Also, this post is in no way based on any inside information from Ekahau, nor is it anything official from them – this is simply an analysis of the contents of the project file that anyone could do, whose nature as a zipped file full of JSON has been known for quite some time.
“I’m gonna get some tags… This is f’ing awesome”
Probably the coolest new feature in v 10.2 is the ability to add key:value tags to stuff. You can apply these tags to APs, either just the tag by itself, or a tag with a value associated with it. The Quick Select also lets you select any APs that have a particular tag key (although somehow they missed the ability to refine based on tag value, which I hope will be corrected in the near future).
Why is this useful? This allows you to add free-form information to access points, whether simulated or measured, that allows Ekahau to be more than just an RF simulation tool, and extends it into a full blown planning and deployment tool. Tagged information can be any kind of metadata you wish. things like:
Mounting hardware
Wired MAC address
AP Group
Serial Number
Zone
Switch
Port
Cable
IDF
… and the list is nearly endless.
This is in addition to the already rich metadata that is associated with the AP that are directly relevant to the RF modeling, such as mounting height, mounting surface, antenna angles, power, channel, antenna types, and so forth.
So how does it work? Pretty simple: on an AP, simply open the sushi menu at the top right, select “Tag AP”. You can also do this from the Edit AP or bulk edit screen when doing multiple APs. This will give you a list of existing tag keys already associated with the project (as well as tags you’ve used before on other projects), along with a free form box to enter your own, or add a value.
As of right now, there’s not a whole lot you can do within the Ekahau software once you have those tags (I would LOVE a table view of my APs and all the metadata, as well as ability to import/export to CSV or Excel), nor is template-based reporting on those tags documented at this point (although I expect they’re working diligently to document this). One key weakness of the template reporting system is that it all has to go through Microsoft Word (with a whole bunch of limitations imposed by that format), and that gets really hairy once you start creating data tables, especially if you want them in Excel or something else.
Side note: Using Excel as a database is really a terrible use of a spreadsheet, but it happens all. the. time.
Which brings me to manipulating/extracting your data by building your own tools. Several people have been doing this unofficially for years, but Ekahau doesn’t offer anything for this… yet.
I mentioned earlier that Ekahau’s data is stored mostly in JSON, which makes it really easy to work with using Python (or, for that matter, Java or perl if you’re into self-flagellation). Every object in the data file has an ID that ties it back to other objects. And that’s the key thing (literally). There are about 2 dozen separate files that track various data, and that’s how they all tie together. Notes and tag keys are each kept in their own file, while the AP data file has a data object that contains a list of the note IDs, and another that keeps a list of tag IDs and the value associated with that tag:
One thing you can do with simulatedRadios.json is go through and adjust your antenna orientations to the nearest 5 or 15 degree increments – having decimal granularity in the antenna orientation isn’t really useful unless you’re doing some very long point to point shots, and it will make the maps look cleaner when your antenna is at 90° instead of 88.6367879° because you manually rotated it by dragging it with the mouse.
I’m also going to omit the antennaTypes.json here, but it’s worth noting that if you have any custom APs/Antennas in your Ekahau setup, that data is included in your project file for portability, and you don’t need that custom config replicated on the next machine that opens up this file, and aren’t limited to the APs and antennas that Ekahau offers by default (although it would be really nice if they made it easy to add custom APs/antennas that survived a code update)
So here’s the basic process to report on your tags and notes:
bring in the list of access points from accessPoints.json. This will get you a list of notes, as well as the tag key IDs, along with that tag’s values.
You’ll need to then cross-reference the tag key IDs from tagKeys.json to get the key values (this approach seems a little convoluted at first, but ensures that a key value can be consistent from one file to the next based on not merely the text in the key value, which will come in to play when merging multiple data files into one. Ekahau was very smart about designing it this way.)
Extract any notes from notes.json.
Cross-reference any additional radio-specific data you need (including orientation) by looking for the access point ID in simulatedRadios.json
Cross-reference any antenna pattern data by looking for the access point ID in antennaTypes.json.
information such as floor number lurks in buildingFloors.json and buildings.json.
and so forth.
Hopefully you’re starting to get the general idea of how this data is put together. It should be a fairly straightforward matter of running a little code against the data file and being able to generate not only a drop list for your installation contractor, but also a big chunk of your configuration script for deploying against your wireless controller. If you’re feeling especially adventurous and saucy, you can even use your wireless system’s API for this and be able to orchestrate a large chunk of your configuration from within Ekahau.
Once I build some actual code, I’ll be sure to share it here.
Here is the big gnarly mind map of the Ekahau data file. It’s probably still very much incomplete and I don’t promise 100% accuracy of data types, but it gives a good visual reference of how the whole thing goes together:
I’ve been doing a little Raspberry Pi hacking lately, and put together a neat way to have physical status LEDs on your desk for things like EC2 instances.
The Hardware
In its most basic form, you can simply hook up an LED and a bias resistor between a ground line and a GPIO line on the Pi, but that doesn’t scale especially well – You can run out of GPIO lines pretty quickly, especially if you’re doing different colors for each status. Plus, it’s not overly elegant.
The solution? Unicorns!
No, really. The fine folks at Pimoroni in Sheffield, UK have made a lovely little HAT device for the Pi called a Unicorn. Its primary purpose is lots of blinky lights to make pretty rainbows and stuff, hence the name. However, this HAT is a 4×8 (or an 8×8) array of RGB LEDs, addressable via the I2C bus, which doesn’t eat up a line per LED (good thing, otherwise it would require 96 analog lines). The unicornhat library (python3-unicornhat) is available for Python 2 and Python 3 in the Raspbian repo. When installed onto the Pi, the Unicorn will fit within a standard Raspberry Pi case.
The Code
This is my first foray into Python, so there was a bit of a learning curve. If you’re familiar with object-oriented code concepts, this should be easy for you. Python is much more parsimonious with punctuation than PHP or perl are.
For accessing the EC2 data, we’ll need Amazon’s boto3 library, also available in the Raspbian repo (python3-boto). One area where boto3 is really nice is that the data is returned directly as a dict object (what users of other languages would call an array), so you don’t have to mess with converting JSON or XML into an object structure, and it can be manipulated as you would any other associative array (or a hash for you old-timers that use perl). AWS returns a fairly complex object, so you kind of have to dig into it via a few iterative loops to extract the data you’re after.
From there, it’s a matter of assigning different RGB values to the states. I chose these ones:
stopped: red
pending: green
running: blue
stopping: yellow(ish)
I also discovered that I needed to assign a specific pixel to each instance ID, otherwise they tended to move around a bit depending on what order AWS returned them on a particular request.
Here’s what the second iteration looks like in action:
import boto3 as aws
import unicornhat as unicorn
import time
# Initialize the Unicorn
unicorn.clear()
unicorn.show()
unicorn.brightness(0.5)
# Create an EC2 object
ec2 = aws.client('ec2')
# Define colors and positions
color = {}
color['stopped']={'red':255,'green':0,'blue':0}
color['pending']={'red':64,'green':255,'blue':0}
color['running']={'red':32,'green':32,'blue':255}
color['stopping']={'red':192,'green':128,'blue':32}
pixel = {}
pixel['i-0fa4ea2560aa17ffd']={'x':0,'y':0}
pixel['i-06b95cd864acb1a8c']={'x':0,'y':1}
pixel['i-0661da0f50ffb604c']={'x':0,'y':2}
pixel['i-063ec151e0f44ef9b']={'x':0,'y':3}
pixel['i-02c514ca567d8a033']={'x':0,'y':4}
# Loop until forever
while True:
response = ec2.describe_instances()
statetable = {}
resarray = response['Reservations']
for res in resarray:
instarray = res['Instances']
for inst in instarray:
iid = inst['InstanceId']
state = inst['State']['Name']
# print(iid)
# print(state)
statetable[iid] = state
for ec2inst in statetable:
x = pixel[ec2inst]['x']
y = pixel[ec2inst]['y']
r = color[statetable[ec2inst]]['red']
g = color[statetable[ec2inst]]['green']
b = color[statetable[ec2inst]]['blue']
# print(x,y,r,g,b)
unicorn.set_pixel(x,y,r,g,b)
unicorn.show()
time.sleep(1)
For the moment, this is just monitoring EC2 status, but I’m going to be adding checks in the near future to do things like ping tests, HTTP checks, etc. Stay tuned.
Linking today to some great content from another Ian (ProTip: get to know an Ian, we’re full of useful knowledge). Ian Morrish posts about automating a variety of methods of automating A/V equipment using PowerShell. Lots of useful stuff in here.