
Yesterday, I posted about leveraging the Meridian API to get a list of placemarks into a CSV file. Today, We’ll take that one step further, and go the other way – because bulk creating/updating placemarks is no fun by hand.
For instance, in this project, I created a bunch of placemarks called “Phone Room” (didn’t know what else to call them at the time). There were several of these on multiple floors. To rename them in the Meridian Editor, I would have to click on each one, rename it, and save.
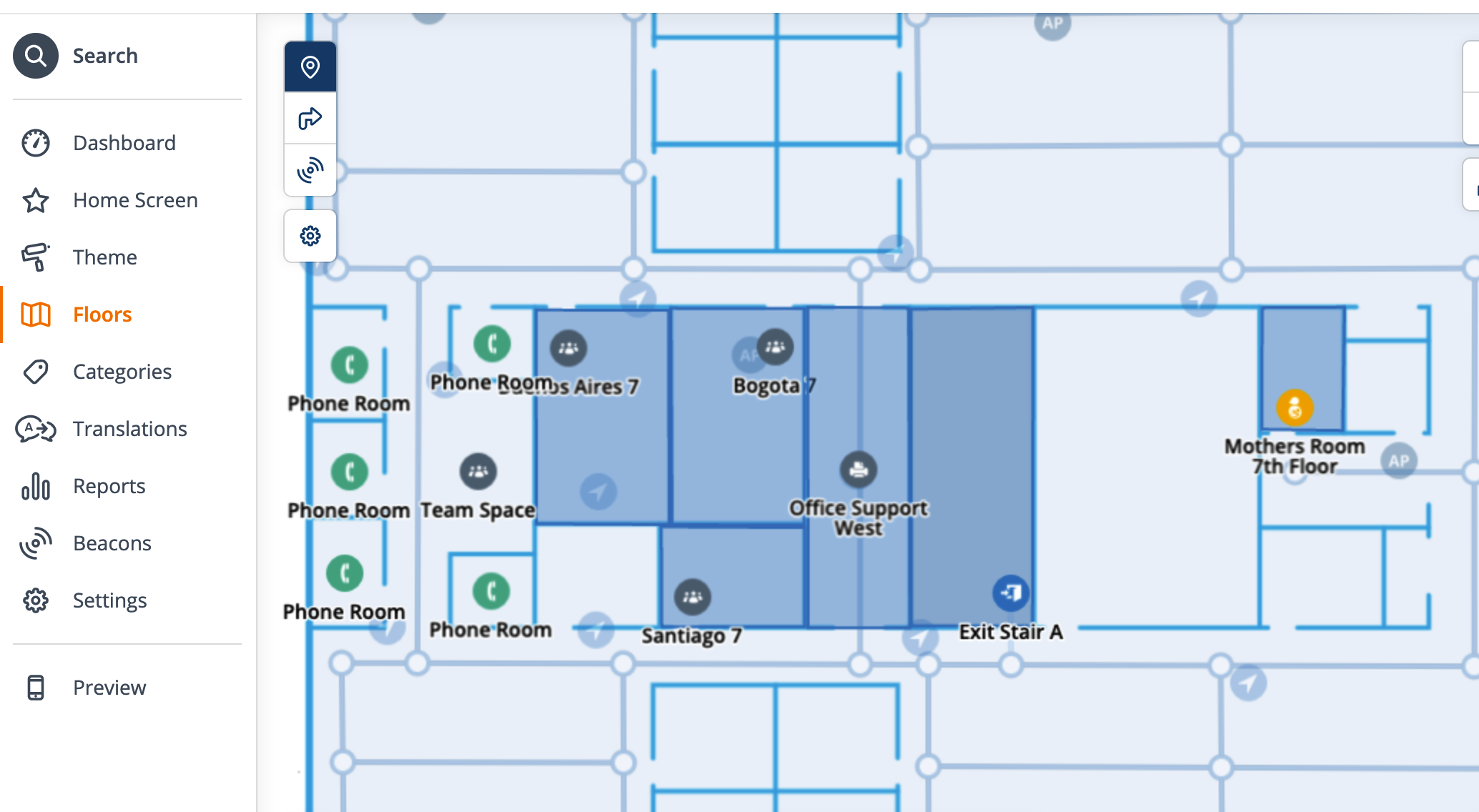
So, once I got guidance on what they were to be called, I fired up Excel and opened up the CSV that I created yesterday, and made the changes in bulk, and then ran them back into Meridian the other way – I changed the name, the type, and the icon:

Sounds easy, right?
Not so much. I ran into some trouble when I opened it in excel, and all my map IDs looked like this:

This is because Excel is stupid, but trying to be smart. It sees those as Really Big Numbers, and converts them to scientific notation, because the largest it can store is a 15-digit integer. And of course, these map IDs are… 16 digits. But I can’t just convert them back as integer number formatting because it then takes the first 15 digits and adds a zero. This, of course, breaks the whole thing. Excel will also do some similar shenanigans when parsing interface names from AOS or Cisco that look like “2/1/4”, which excel assumes is a date, because excel assumes everything that looks vaguely numeric must be a number, because it is a spreadsheet after all, and spreadsheets are made for numbers, even if people abuse them all the time as a poor substitute for a database.
So, this means you either have to make the changes directly in the CSV with a text editor, or find another sheets application that doesn’t mangle the map IDs. Fortunately, for us Mac users, Apple’s spreadsheet application (“Numbers”) handles this just fine. So make the changes, export to CSV, and run it all back into the API. (you can also name it as a .txt and manually import into Excel and specify that as a text column, but that’s tedious, which is what we’re trying to avoid)
I’ve built a bit of smarts into this script, since I don’t want to break things on Meridian’s end (although Meridian does a great job of sanity checking and sanitizing the input data from the API). The first thing it does is grab a list of available maps for the location. Then it goes through all the lines in the spreadsheet, converts them to the JSON payload that Meridian wants, and checks to see if there’s existing data in the id field. If there is, it assumes that this is an update (it does not, however, check to see if the data already matches the existing placemark since Meridian does that already when you update). If there is no ID, it assumes that this is a new object to be created, and verifies that it has the minimum required information (name, map, and x/y position), and in both cases, checks to make sure the map data in the object is a map ID that exists at this location (this is how I found out that excel was mangling them)
Running the script spits out this for each row in the CSV that it considers an update:
Update object id XXXXXXXXXXXXXXX_5666694473318400
object update passed initial sanity checks and will be placed on 11th Floor.
Updating existing object with payload:
{
"id": "XXXXXXXXXXXXXXX_5666694473318400",
"name": "Huddle Space",
"map": "XXXXXXXXXXXXXXX",
"type": "conference_room",
"type_name": "Conference Room",
"color": "f2af1d",
"x": "177.20516072322900",
"y": "597.6184874989240",
"latitude": 41.94822,
"longitude": -87.65552,
"area": "",
"description": "",
"phone": "",
"email": "",
"url": ""
}
Object ID XXXXXXXXXXXXXXX_5666694473318400 named Huddle Space updated on map XXXXXXXXXXXXXXXXIf it doesn’t find an id and determines that an object needs to be created, it goes down like this:
Create new object:
object create passed initial sanity checks and will be placed on 11th Floor.
Creating new object with payload:
{
"name": "Test Placemark",
"map": "XXXXXXXXXXXXXXXX",
"type": "generic",
"type_name": "Placemark",
"color": "f2af1d",
"x": "400",
"y": "600",
"latitude": "",
"longitude": "",
"area": "",
"description": "",
"phone": "",
"email": "",
"url": "https://arubanetworks.,com"
}
Object not created. Errors are
{
"url": [
"Enter a valid URL."
]
}
As you can see here, I made a typo in the URL field, and the data returned from the API call lists the fields that contain an error. If the call is successful, it returns an ID, which the script checks for to verify success. The response from a successful API call looks like this :
{
"parent_pane": "",
"child_pane_ne": "",
"child_pane_se": "",
"child_pane_sw": "",
"child_pane_nw": "",
"left": -1,
"top": -1,
"width": -1,
"height": -1,
"next_pane": null,
"next_id": "5484974943895552",
"modified": "2021-08-11T15:12:52",
"created": "2021-08-11T15:12:52",
"id": "XXXXXXXXXXXXXXXX_5484974943895552",
"map": "XXXXXXXXXXXXXXXX",
"x": 400.0,
"y": 600.0,
"latitude": 41.94822,
"longitude": -87.65552,
"related_map": "",
"name": "Test Placemark",
"area": null,
"hint": null,
"uid": null,
"links": [],
"type": "generic",
"type_category": "Markers",
"type_name": "Placemark",
"color": "88689e",
"description": "",
"keywords": null,
"phone": "",
"email": "",
"url": "https://arubanetworks.com",
"custom_1": null,
"custom_2": null,
"custom_3": null,
"custom_4": null,
"image_url": null,
"image_layout": "widescreen",
"is_facility": false,
"hide_on_map": false,
"landmark": false,
"feed": "",
"deep_link": "com.arubanetworks.aruba-meridian://ZZZZZZZZZZZZZZZZ/placemarks/XXXXXXXXXXXXXXXX_5484974943895552",
"is_disabled": false,
"category_ids": [],
"categories": []
}Of course, the script doesn’t have to spit out all that output, but it’s handy to follow what’s going on. Comment out the print lines if you want it to shut up.
So, without further ado, here’s the script. This has not been debugged extensively, so use at your own risk. If you break your environment, you probably should have tested it in the lab first.
Meridian CSV Placemark Import#!/usr/bin/python3 # Aruba Meridian Placemark Import from CSV # (c) 2021 Ian Beyer # This code is not endorsed or supported by HPE import json import requests import csv import sys auth_token = '<please insert a token to continue>' location_id = 'XXXXXXXXXXXXXXXX' baseurl = 'https://edit.meridianapps.com/api/locations/'+location_id header_base = {'Authorization': 'Token '+auth_token} def api_call(method,endpoint,headers,payload): response = requests.request(method, baseurl+endpoint, headers=headers, data=payload) resp_json = json.loads(response.text) return(resp_json) #File name argument #1 try: fileName = str(sys.argv[1]) except: print("Exception: Enter file to use") exit() # Get available maps for this location for sanity check maps={} # print("Available Maps: ") for floor in api_call('GET','/maps',header_base,{})['results']: maps[floor['id']] = floor['name'] # print (floor['name']+ ": "+ floor['id']) import_data_file = open(fileName, 'rt') csv_reader = csv.reader(import_data_file) count = 0 objects = [] csv_fields = [] for line in csv_reader: placemark = {} # Check to see if this is the header row and capture field names if count < 1 : csv_fields = line else: # If this is a data row, capture the fields and put them into a dict object fcount = 0 for fields in line: objkey = csv_fields[fcount] placemark[objkey] = line[fcount] fcount += 1 # Add the placemark object into the object list objects.append(placemark) count +=1 #print(json.dumps(objects, indent=2)) import_data_file.close() #Check imported objects for create or update. If it has an ID, then update. for pm in objects: task = 'ignore' if pm['id'] == "" : task = 'create' print("Create new object: ") # Delete id from payload del pm['id'] else: task = 'update' print("Update object id "+ pm['id']) # Remove floor from payload as it is not valid del pm['floor'] # Check to see if the basics are there before making the API calls reject = [] if pm['x'] == "": reject.append("Missing X coordinate") if pm['y'] == "": reject.append("Missing Y coordinate") if pm['map'] == "": reject.append("Missing map id") if pm['name'] == "": reject.append("Missing object name") if len(reject)>0: #print("object "+ task + " rejected due to missing required data:") for reason in reject: print(reason) task = 'ignore' else: if maps.get(pm['map']) == None: print ("Map ID "+pm['map']+" Not found in available maps. Object will not be created. ") task = 'ignore' else: print("object "+ task + " passed initial sanity checks and will be placed on "+ maps[pm['map']] +".") #print ("Object Payload:") #print (json.dumps(pm, indent=2)) method = 'GET' if task == 'create': #print ("Creating new object with payload:") #print (json.dumps(pm, indent=2)) method = 'POST' ep = '/placemarks' result = api_call(method,ep,header_base,pm) if result.get('id') != None: print ("Object ID "+result['id']+" named "+result['name']+ " created on map "+ result['map']) else: print ("Object not created. Errors are") print (json.dumps(result, indent=2)) if task == 'update': #print ("Updating existing object with payload:") #print (json.dumps(pm, indent=2)) method = 'PATCH' ep = '/placemarks/'+pm['id'] result = api_call(method,ep,header_base,pm) if result.get('id') != None: print ("Object ID "+result['id']+" named "+result['name']+ " updated on map "+ result['map']) else: print ("Object not updated. Errors are") print (json.dumps(result, indent=2)) baseurl = 'https://edit.meridianapps.com/api/locations/'+location_id header_base = {'Authorization': 'Token '+auth_token} def api_call(method,endpoint,headers,payload): response = requests.request(method, baseurl+endpoint, headers=headers, data=payload) resp_json = json.loads(response.text) return(resp_json) # Get available maps for this location for sanity check maps={} # print("Available Maps: ") for floor in api_call('GET','/maps',header_base,{})['results']: maps[floor['id']] = floor['name'] # print (floor['name']+ ": "+ floor['id']) # I've hard coded the file name here because I'm lazy. import_data_file = open('placemarks_update.csv', 'rt') csv_reader = csv.reader(import_data_file) count = 0 objects = [] csv_fields = [] for line in csv_reader: placemark = {} # Check to see if this is the header row and capture field names if count < 1 : csv_fields = line else: # If this is a data row, capture the fields and put them into a dict object fcount = 0 for fields in line: objkey = csv_fields[fcount] placemark[objkey] = line[fcount] fcount += 1 # Add the placemark object into the object list objects.append(placemark) count +=1 #print(json.dumps(objects, indent=2)) import_data_file.close() #Check imported objects for create or update. If it has an ID, then update. for pm in objects: task = 'ignore' if pm['id'] == "" : task = 'create' print("Create new object: ") # Delete id from payload del pm['id'] else: task = 'update' print("Update object id "+ pm['id']) # Remove floor from payload as it is not valid del pm['floor'] # Check to see if the basics are there before making the API calls reject = [] if pm['x'] == "": reject.append("Missing X coordinate") if pm['y'] == "": reject.append("Missing Y coordinate") if pm['map'] == "": reject.append("Missing map id") if pm['name'] == "": reject.append("Missing object name") if len(reject)>0: #print("object "+ task + " rejected due to missing required data:") for reason in reject: print(reason) task = 'ignore' else: if maps.get(pm['map']) == None: print ("Map ID "+pm['map']+" Not found in available maps. Object will not be created. ") task = 'ignore' else: print("object "+ task + " passed initial sanity checks and will be placed on "+ maps[pm['map']] +".") #print ("Object Payload:") #print (json.dumps(pm, indent=2)) method = 'GET' if task == 'create': #print ("Creating new object with payload:") #print (json.dumps(pm, indent=2)) method = 'POST' ep = '/placemarks' result = api_call(method,ep,header_base,pm) if result.get('id') != None: print ("Object ID "+result['id']+" named "+result['name']+ " created on map "+ result['map']) else: print ("Object not created. Errors are") print (json.dumps(result, indent=2)) if task == 'update': #print ("Updating existing object with payload:") #print (json.dumps(pm, indent=2)) method = 'PATCH' ep = '/placemarks/'+pm['id'] result = api_call(method,ep,header_base,pm) if result.get('id') != None: print ("Object ID "+result['id']+" named "+result['name']+ " updated on map "+ result['map']) else: print ("Object not updated. Errors are") print (json.dumps(result, indent=2))
It’s also worth noting here that the CSV structure and field order isn’t especially important since it reads in the header row to get the keys for the dict – as long as you have the minimum data (name/map/x/y) you can create a table of new objects from scratch. Any valid field can be used (although categories requires some additional structure)
Questions/comments/glaring errors? Comment section is right here. Scripts on this page can also be found on github.
Pingback: Location, Location, Location – The CaNerdIan